Volgens Ismail moeten de onderzoeksvragen nog worden geformuleerd. Door matige bereikbaarheid van stakeholders verloopt dit langzaam.
Ik zal contact zoeken met Dennis Ismail en vragen wat er nog nodig is.
Besproken Appointment Scheduling
Nieuwe opzet en berekening getoond:
Andere wijze van sampling >> grotere spreiding van schedules >> hogere error
Intermediate training: Tijdens local search wordt het model bijgetraind.
Ger is tevreden over de kwaliteit van de optimale schedule.
Onderzoeken waar de grote waarde op het einde vandaan komt >> Objective value berekening naar Joost sturen voor controle.
Idee: we gaan ons meer richten op onderzoek naar de structuur van optimale schedules. Ger noemde ‘splining’ (?), Witek: autoencoders, Joost: maak verschillende types schedules (rustig, gemiddeld, druk) en probeer daaruit de basiscomponenten te destileren van optimale schedules.
Termen:
representation learning
Latent Feature Analysis
short-term memory network-embedded autoencoder model
learning-based genetic algorithm (LGA)
representation learning
Quote Ger: “AI is alles wat een computer nog niet kan.”
Visualizing a Poisson Distribution
The Poisson distribution is a discrete probability distribution that models the number of times an event occurs in a fixed interval of time or space. It is particularly useful when these events occur independently and the average rate (( )) is known.
Understanding the Poisson Distribution
Probability Mass Function (PMF)
The PMF of the Poisson distribution gives the probability of observing exactly ( k ) events in a given interval:
( k ): The number of occurrences of the event (non-negative integer).
( ): The average rate (mean number of occurrences in the interval).
( e ): Euler’s number, approximately equal to 2.71828.
Properties
Mean: ( )
Variance: ( )
Key Assumptions:
Events occur independently.
The probability of more than one event occurring in an infinitesimally small interval is negligible.
Visualizing the Poisson Distribution with Python
We can visualize the Poisson distribution using Python’s matplotlib and scipy.stats libraries.
Code Example: Plotting the PMF
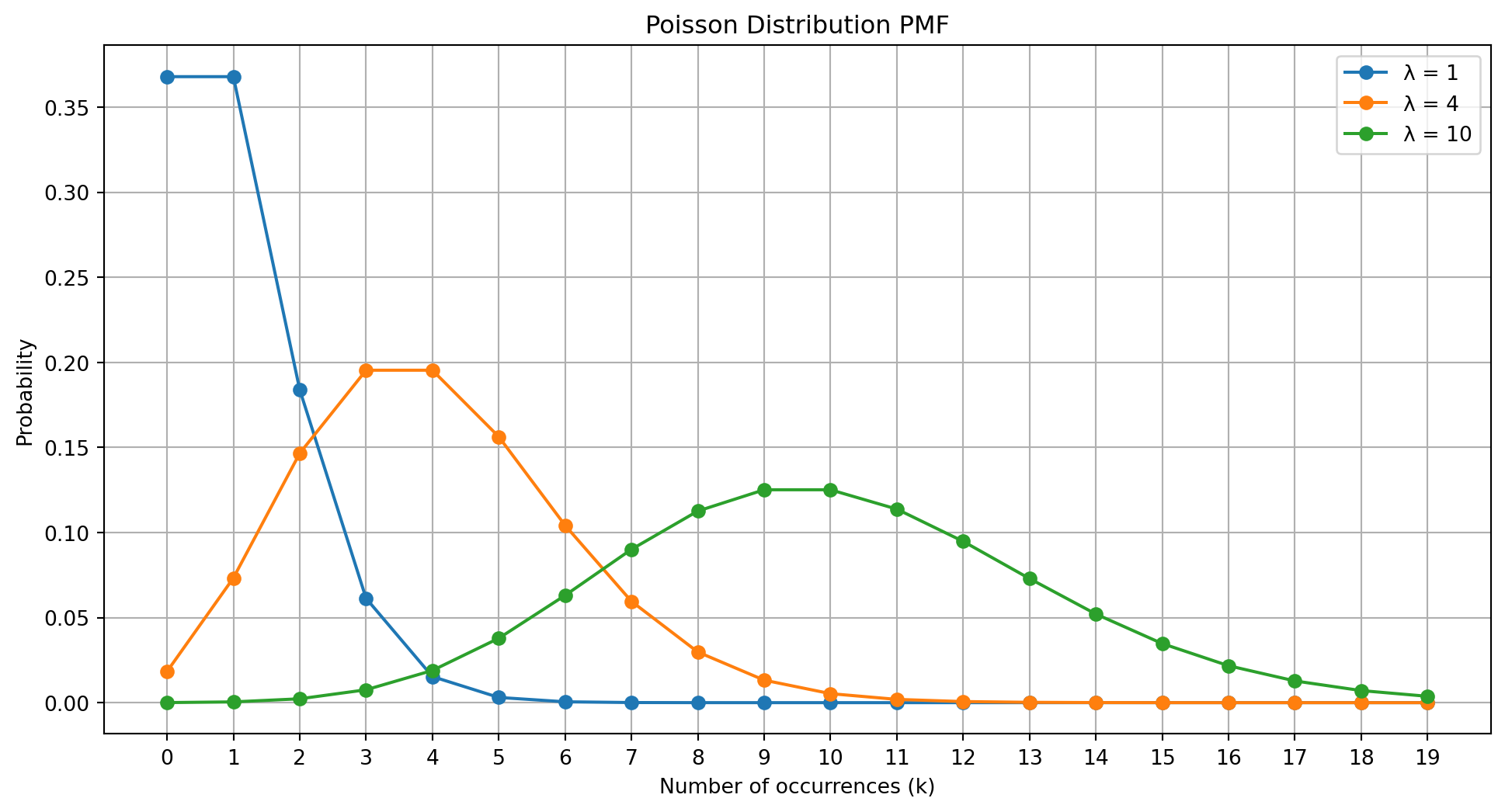
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import poisson# Define lambda values (average rates)lambda_values = [1, 4, 10]# Define the range of k values (number of occurrences)k = np.arange(0, 20)plt.figure(figsize=(12, 6))for lam in lambda_values:# Calculate the PMF for each k pmf = poisson.pmf(k, mu=lam)# Plot the PMF plt.plot(k, pmf, marker='o', linestyle='-', label=f'λ = {lam}')plt.title('Poisson Distribution PMF')plt.xlabel('Number of occurrences (k)')plt.ylabel('Probability')plt.xticks(k)plt.legend()plt.grid(True)plt.show()
Output:
Poisson PMF Plot
Note: Since I cannot display images directly, please run the code to see the visualization.
Explanation
Libraries:
numpy: For numerical operations.
matplotlib.pyplot: For plotting graphs.
scipy.stats.poisson: For Poisson distribution functions.
Parameters:
lambda_values: A list of different ( ) values to compare how the distribution changes.
k: A range of integer values representing the number of occurrences.
Plotting:
For each ( ), compute the PMF across all ( k ).
Use plt.plot() to create line plots with markers.
Observations
λ = 1:
The distribution is heavily skewed to the left.
Highest probability at ( k = 0 ) and ( k = 1 ).
λ = 4:
The peak shifts to ( k = 4 ).
The distribution becomes wider.
λ = 10:
The distribution appears more symmetric.
Resembles a normal distribution due to the Central Limit Theorem.
Visualizing the Cumulative Distribution Function (CDF)
The CDF shows the cumulative probability up to a certain number of events.
Code Example: Plotting the CDF
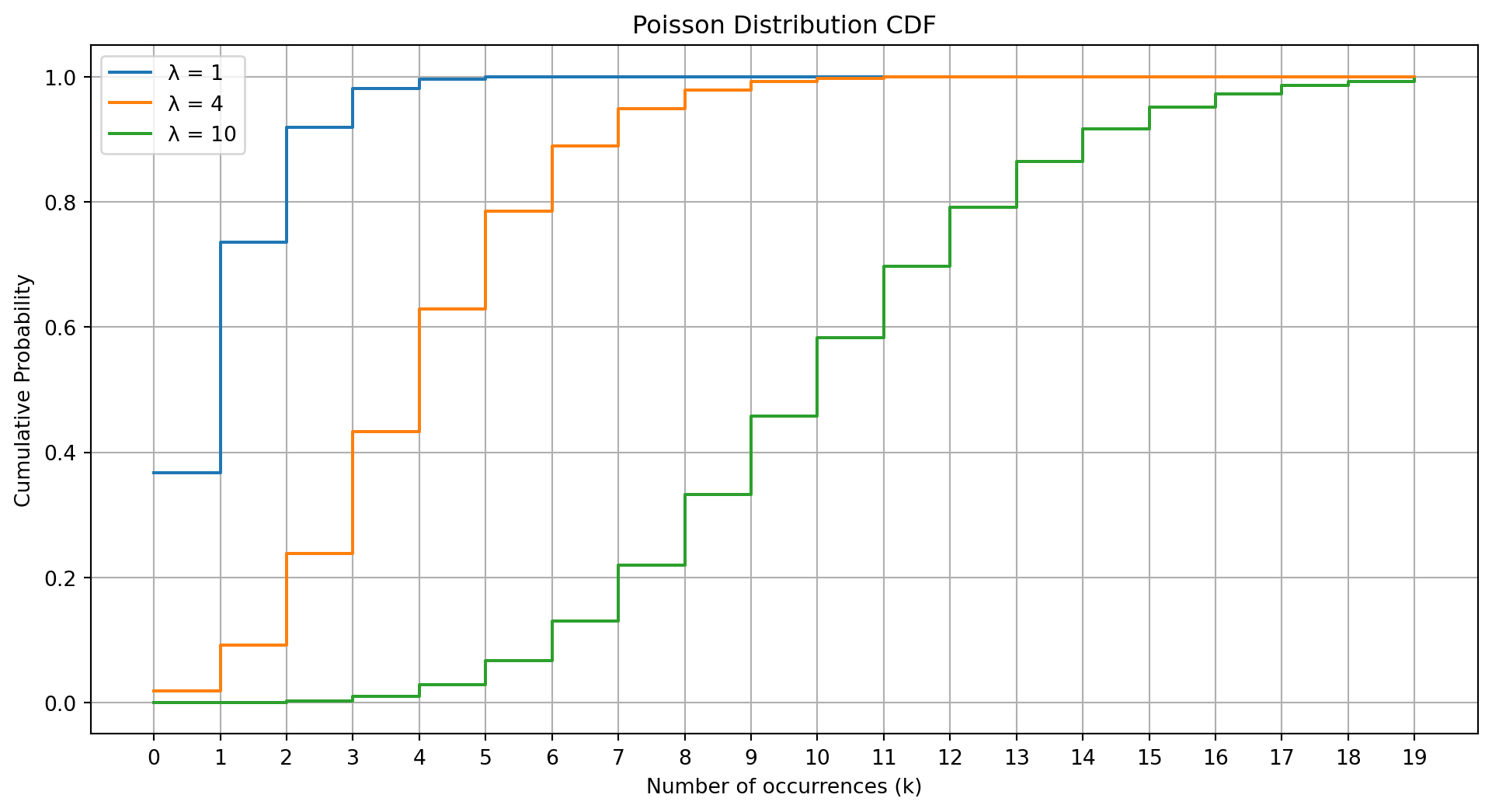
plt.figure(figsize=(12, 6))for lam in lambda_values:# Calculate the CDF for each k cdf = poisson.cdf(k, mu=lam)# Plot the CDF plt.step(k, cdf, where='post', label=f'λ = {lam}')plt.title('Poisson Distribution CDF')plt.xlabel('Number of occurrences (k)')plt.ylabel('Cumulative Probability')plt.xticks(k)plt.legend()plt.grid(True)plt.show()
Output:
Poisson CDF Plot
Explanation
poisson.cdf() computes the cumulative probability up to each ( k ).
plt.step() creates a step plot, which is suitable for discrete distributions.
Simulating Poisson-Distributed Data
We can simulate random data following a Poisson distribution and visualize it.
Code Example: Generating and Plotting Samples
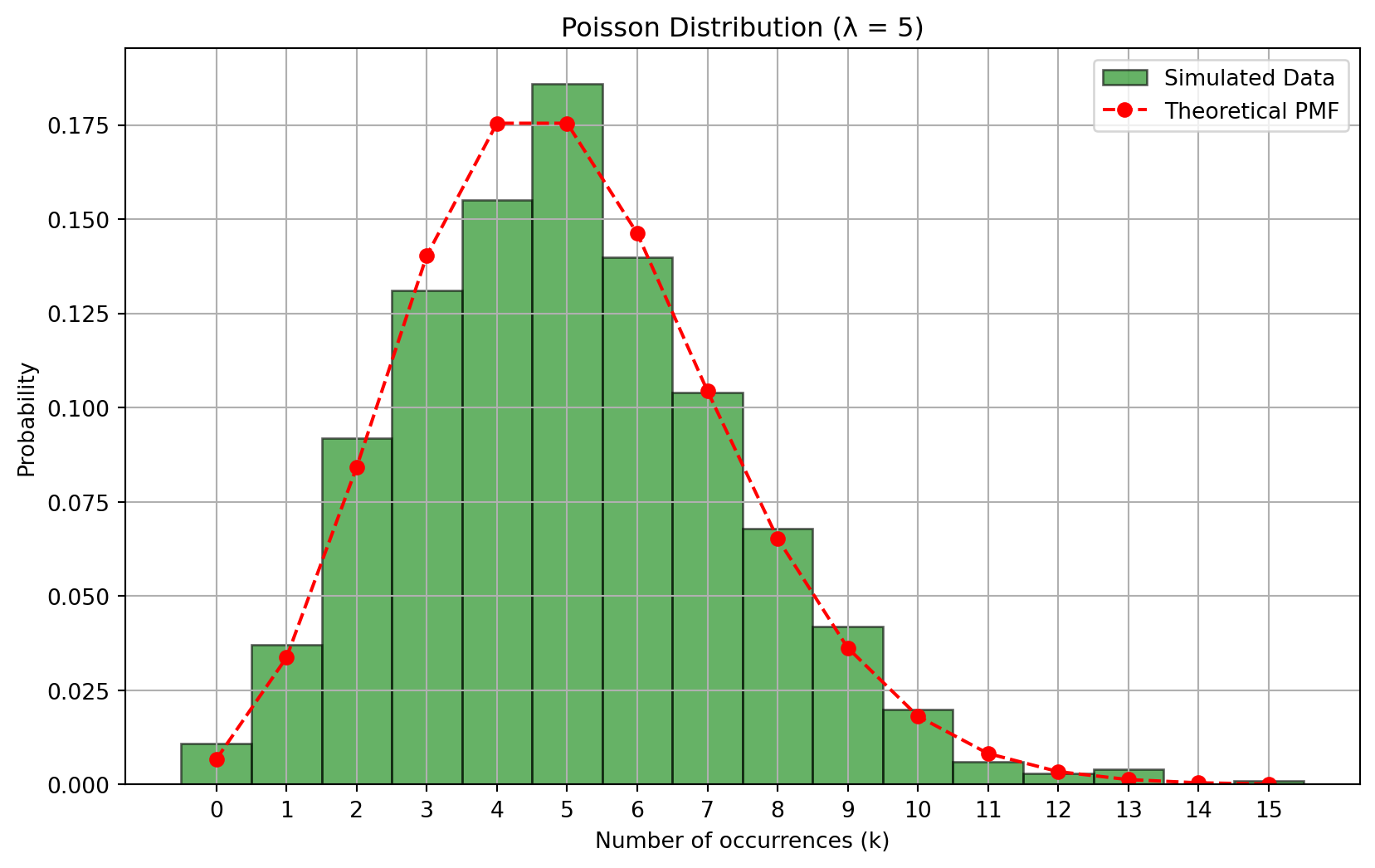
# Generate random sampleslam =5# Choose a lambda valuesamples = np.random.poisson(lam=lam, size=1000)# Plot histogramplt.figure(figsize=(10, 6))bins = np.arange(0, samples.max() +1.5) -0.5# Align bins with integersplt.hist(samples, bins=bins, density=True, alpha=0.6, color='g', edgecolor='black', label='Simulated Data')# Overlay the theoretical PMFk = np.arange(0, samples.max() +1)pmf = poisson.pmf(k, mu=lam)plt.plot(k, pmf, 'r--', marker='o', label='Theoretical PMF')plt.title(f'Poisson Distribution (λ = {lam})')plt.xlabel('Number of occurrences (k)')plt.ylabel('Probability')plt.xticks(k)plt.legend()plt.grid(True)plt.show()
Output:
Poisson Sample Histogram
Explanation
Sampling:
Use np.random.poisson() to generate 1000 random samples with ( = 5 ).
Histogram:
Align the histogram bins with integer values for accurate representation.
Overlay PMF:
Plot the theoretical PMF on top of the histogram for comparison.
Understanding the Results
The histogram of simulated data closely follows the theoretical PMF.
This demonstrates the accuracy of the Poisson model in representing discrete event occurrences.
Practical Applications
Queueing Theory: Modeling the number of customers arriving at a service center.
Telecommunications: Number of packets arriving at a network router.
Astronomy: Counting the number of photons detected by a telescope.
Finance: Modeling the number of trades executed in a time interval.
Biology: Counting the number of mutations in a strand of DNA over a period.
Interactive Visualization (Optional)
If you’re using an interactive environment like Jupyter Notebook, you can create sliders to adjust ( ) dynamically.
Code Example: Interactive Plot
from ipywidgets import interactdef plot_poisson(lam): k = np.arange(0, 20) pmf = poisson.pmf(k, mu=lam) plt.figure(figsize=(8, 5)) plt.plot(k, pmf, marker='o', linestyle='-', label=f'λ = {lam}') plt.title('Poisson Distribution PMF') plt.xlabel('Number of occurrences (k)') plt.ylabel('Probability') plt.xticks(k) plt.legend() plt.grid(True) plt.show()interact(plot_poisson, lam=(0.1, 20, 0.1))
<function __main__.plot_poisson(lam)>
Explanation
interact: Creates an interactive slider for ( ).
Adjust the slider to see how the Poisson distribution changes with different ( ) values.
Note: This requires running in an environment that supports ipywidgets.
Conclusion
Visualizing the Poisson distribution helps in understanding the behavior of events that occur independently over a fixed interval. By adjusting ( ), you can see how the distribution shifts and changes shape.
Certainly! Let’s create a very small example of the appointment scheduling problem with 5 patients and 3 time intervals. We’ll code this example in Python and visualize the latent space, which in this context will represent different scheduling configurations and their corresponding objective function values.
Problem Setup
Number of Patients (N): 5
Number of Time Intervals (T): 3
No-Show Probability (q): 0.20
Weight for Waiting Time (w): 0.1
Service Time Distribution: We’ll assume service times can be 1, 2, or 3 units with equal probability.
Generate All Possible Schedules: Each patient can be scheduled in any of the 3 intervals. Since overbooking is allowed, the total number of possible schedules is ( 3^5 = 243 ).
Simulate No-Show Scenarios: For each schedule, each patient has a 20% chance of not showing up. There are ( 2^5 = 32 ) possible no-show combinations.
Compute Expected Objective Function: For each schedule, calculate the expected total waiting time and doctor’s overtime across all no-show scenarios.
Visualization: Plot the schedules against their expected objective function values to visualize the latent space.
Code Implementation
Below is the Python code implementing the above steps.
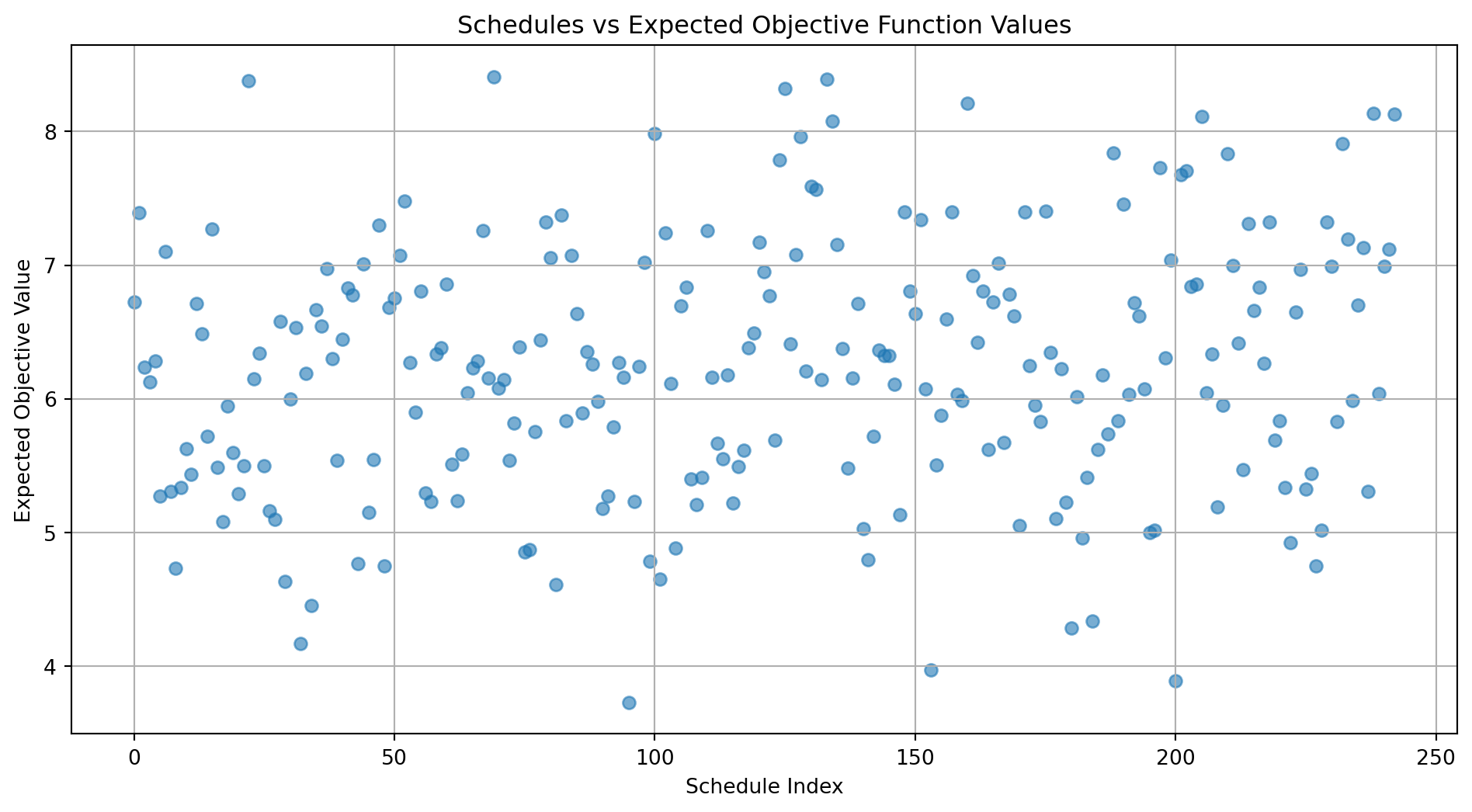
import itertoolsimport numpy as npimport matplotlib.pyplot as plt# ParametersN =5# Number of patientsT =3# Number of time intervalsq =0.20# No-show probabilityw =0.1# Weight for waiting time# Possible service times and their probabilitiesservice_times = [1, 2, 3] # Possible service durationsservice_probabilities = [1/3, 1/3, 1/3] # Equal probabilities# Generate all possible schedules (243 in total)time_intervals =range(T)all_schedules =list(itertools.product(time_intervals, repeat=N))# Generate all possible no-show combinations (32 in total)no_show_combinations =list(itertools.product([0, 1], repeat=N)) # 1: shows up, 0: no-showno_show_probabilities = [((1- q) **sum(ns)) * (q ** (N -sum(ns))) for ns in no_show_combinations]# Function to calculate expected objective for a scheduledef calculate_expected_objective(schedule): expected_waiting_time =0 expected_overtime =0for ns, ns_prob inzip(no_show_combinations, no_show_probabilities):# Patients who show up patients_present = [i for i inrange(N) if ns[i] ==1]ifnot patients_present:continue# No patients showed up in this scenario# Assign patients to their scheduled intervals scheduled_times = [schedule[i] for i in patients_present]# Simulate service times service_times_samples = np.random.choice(service_times, size=len(patients_present), p=service_probabilities)# Sort patients by scheduled time sorted_patients =sorted(zip(patients_present, scheduled_times, service_times_samples), key=lambda x: x[1])# Calculate waiting times and finish times current_time =0 total_waiting_time =0for patient_id, scheduled_time, service_time in sorted_patients: arrival_time = scheduled_time waiting_time =max(0, current_time - arrival_time) total_waiting_time += waiting_time current_time =max(current_time, arrival_time) + service_time# Doctor's overtime overtime =max(0, current_time - T)# Accumulate expected values expected_waiting_time += ns_prob * total_waiting_time expected_overtime += ns_prob * overtime# Objective function objective = w * expected_waiting_time + expected_overtimereturn objective# Calculate expected objectives for all schedulesobjectives = []for schedule in all_schedules: obj = calculate_expected_objective(schedule) objectives.append(obj)# Visualizationplt.figure(figsize=(12, 6))plt.scatter(range(len(all_schedules)), objectives, alpha=0.6)plt.title('Schedules vs Expected Objective Function Values')plt.xlabel('Schedule Index')plt.ylabel('Expected Objective Value')plt.grid(True)plt.show()
Explanation of the Code
Generating Schedules: We use itertools.product to generate all possible assignments of 5 patients to 3 time intervals.
No-Show Combinations: We generate all possible combinations of patients showing up or not. Each combination has an associated probability based on the no-show probability ( q ).
Calculating Expected Objective:
For each schedule, we iterate over all no-show scenarios.
For patients who show up, we simulate their service times.
We calculate waiting times based on the arrival and service times.
We compute the doctor’s overtime as any time the doctor works beyond the total scheduled intervals.
We calculate the expected waiting time and overtime by weighting each scenario with its probability.
The objective function is computed using the given weight ( w ).
Visualization:
We plot the expected objective function values for all schedules.
Each point represents a schedule in the latent space.
Visualization Output
The plot will display the schedule index on the x-axis and the expected objective value on the y-axis. This visualizes the latent space by showing how the expected objective value varies across different scheduling configurations.
Interpreting the Visualization
Clusters: You may observe clusters where schedules have similar objective values. This indicates regions in the latent space where schedules perform similarly.
Optimal Schedules: Schedules with the lowest expected objective values are of interest, as they represent the most efficient scheduling configurations.
Variability: The spread of the objective values demonstrates the impact of scheduling decisions on the performance measures.
Note on Computational Complexity
Random Sampling: Due to computational constraints, especially when simulating stochastic elements like service times and no-shows, the code uses random sampling for service times.
Simplifications: In a real-world scenario, more sophisticated methods like Monte Carlo simulations or optimization algorithms would be employed.
Certainly!
Total Amount of Work in an Interval
Definition:
The total amount of work in a time interval is the sum of the service times required by all patients scheduled in that interval. When multiple patients are scheduled simultaneously (overbooking), the total work is the combined service time needed to attend to all these patients.
Mathematically, if ( k ) patients are scheduled in a particular interval, and each patient’s service time is represented by the random variable ( S_i ), then the total amount of work ( W ) in that interval is:
\[ W = \sum\_{i=1}\^{k} S_i \]
Since the service times ( S_i ) are random variables (assuming they follow the same distribution and are independent), the total work ( W ) is also a random variable. Its distribution is the k-fold convolution of the individual service time distribution.
Convolution of Service Times:
Single Patient (k = 1): The total work is simply the service time of that patient.
Multiple Patients (k > 1): The total work is the sum of the service times of all patients scheduled in that interval.
Why Convolution?
Convolution is a mathematical operation that describes the distribution of the sum of independent random variables. In this context, it’s used to determine the probability distribution of the total work when multiple patients are scheduled together.
Impact on Scheduling
Waiting Times: The total amount of work influences patient waiting times. If the total work exceeds the length of the interval, patients will have to wait longer, and delays may propagate to subsequent intervals.
Doctor’s Overtime: Excessive total work can lead to the doctor working beyond scheduled hours, increasing overtime costs.
Objective Function: Understanding the distribution of the total work helps in estimating expected waiting times and overtime, which are critical components of the objective function to be minimized.
Simplifying by Ignoring No-Shows
To focus on the concept of total work and its implications, we’ll ignore patient no-shows. This means we assume all scheduled patients arrive, simplifying the analysis and allowing us to concentrate on service time variability and scheduling configurations.
Small Example with Visualization
Let’s revisit the small example with 5 patients and 3 time intervals, focusing on the total amount of work in each interval.
Assumptions
Number of Patients (N): 5
Number of Time Intervals (T): 3
Overbooking Allowed: Multiple patients can be scheduled in the same interval.
Service Time Distribution: Service times are 1, 2, or 3 units with equal probability (( ) each).
Generate All Possible Schedules: Each patient can be scheduled in any of the 3 intervals. Since overbooking is allowed, there are ( 3^5 = 243 ) possible schedules.
Calculate Total Work per Interval: For each schedule, determine the total amount of work in each interval by summing the service times of the patients scheduled in that interval.
Compute Waiting Times and Overtime: Based on the total work, calculate the waiting time for patients and any overtime for the doctor.
Visualize: Plot the objective function values for all schedules to visualize how the total amount of work affects the performance measures.
Python Code Implementation
Below is the Python code to implement the above steps.
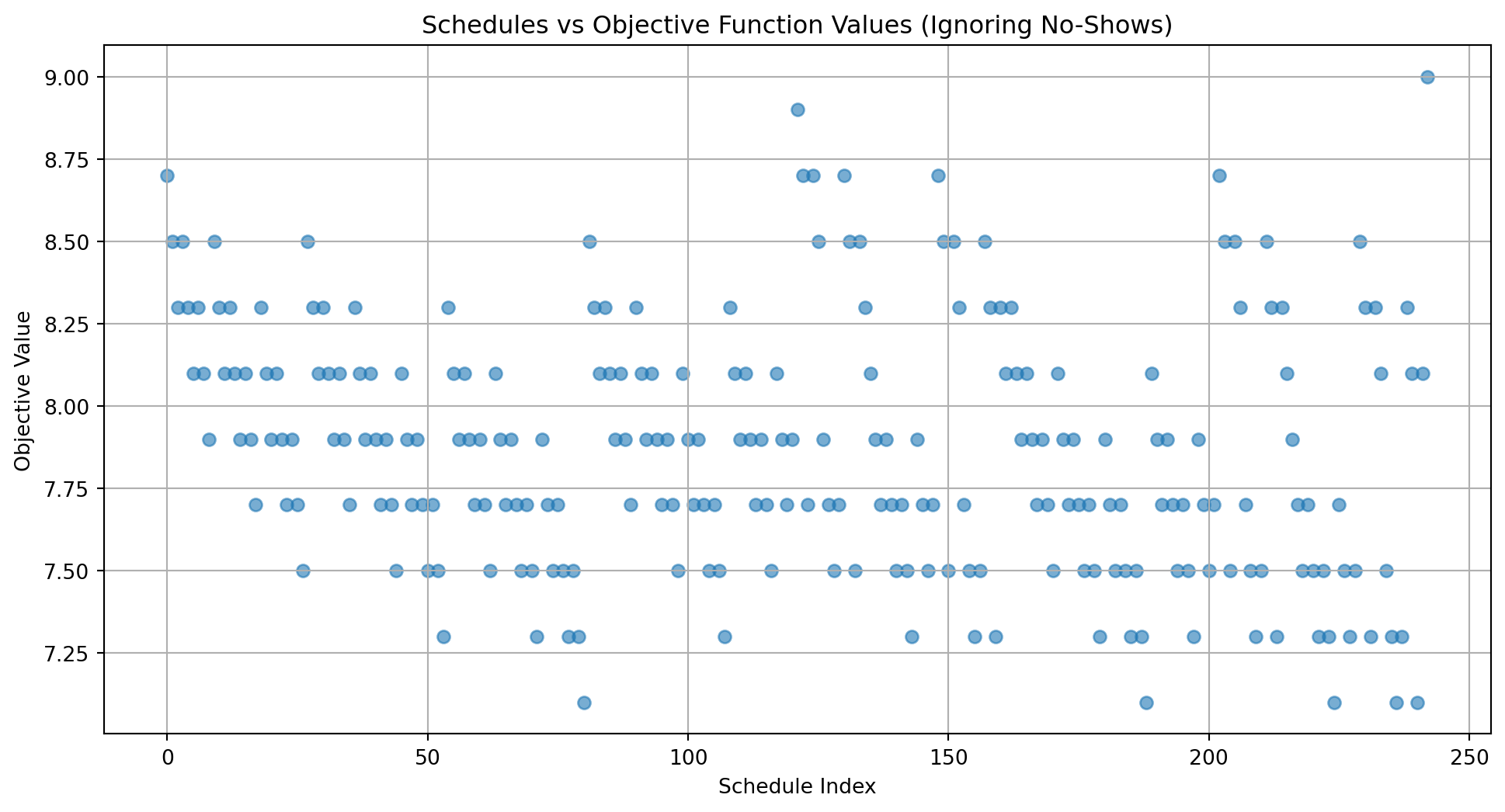
import itertoolsimport numpy as npimport matplotlib.pyplot as plt# ParametersN =5# Number of patientsT =3# Number of time intervalsw =0.1# Weight for waiting timeinterval_length =1# Each interval is 1 unit of time# Possible service times and their probabilitiesservice_times = [1, 2, 3]service_probabilities = [1/3, 1/3, 1/3]# Generate all possible schedulestime_intervals =range(T)all_schedules =list(itertools.product(time_intervals, repeat=N))# Function to calculate the convolution of service timesdef convolve_service_times(k):# Base case for k=1if k ==1:return service_times, service_probabilities# Recursive convolution for k > 1 prev_values, prev_probs = convolve_service_times(k -1) conv_values = [] conv_probs = []for i, v1 inenumerate(prev_values):for j, v2 inenumerate(service_times): conv_values.append(v1 + v2) conv_probs.append(prev_probs[i] * service_probabilities[j])# Combine probabilities for same total service times total_work = {}for v, p inzip(conv_values, conv_probs): total_work[v] = total_work.get(v, 0) + p values =list(total_work.keys()) probs =list(total_work.values())return values, probs# Function to calculate expected waiting time and overtime for a scheduledef calculate_objective(schedule):# Organize patients by their scheduled intervals intervals = {i: [] for i in time_intervals}for patient_id, interval inenumerate(schedule): intervals[interval].append(patient_id)# Initialize variables current_time =0 total_waiting_time =0# Process each intervalfor interval insorted(intervals.keys()): patients_in_interval = intervals[interval] k =len(patients_in_interval)if k ==0: interval_expected_work =0else:# Get the expected total work for k patients values, probs = convolve_service_times(k) interval_expected_work =sum(v * p for v, p inzip(values, probs))# Calculate waiting time (if any) interval_start_time = interval * interval_length waiting_time =max(0, current_time - interval_start_time) total_waiting_time += waiting_time# Update current time current_time =max(current_time, interval_start_time) + interval_expected_work# Calculate doctor's overtime total_scheduled_time = T * interval_length overtime =max(0, current_time - total_scheduled_time)# Compute the objective function objective = w * total_waiting_time + overtimereturn objective# Calculate the objective function for all schedulesobjectives = []for schedule in all_schedules: obj = calculate_objective(schedule) objectives.append(obj)# Visualizationplt.figure(figsize=(12, 6))plt.scatter(range(len(all_schedules)), objectives, alpha=0.6)plt.title('Schedules vs Objective Function Values (Ignoring No-Shows)')plt.xlabel('Schedule Index')plt.ylabel('Objective Value')plt.grid(True)plt.show()
Explanation of the Code
Generating Schedules: We use itertools.product to create all possible ways to assign 5 patients to 3 intervals.
Convolution Function (convolve_service_times):
This function computes the k-fold convolution of the service time distribution to obtain the distribution of the total amount of work when ( k ) patients are scheduled together.
It recursively builds the distribution for ( k ) patients based on the distribution for ( k - 1 ) patients.
Calculating Expected Work:
For each interval, we calculate the expected total work using the convolved distribution.
The expected total work is the sum of each possible total service time multiplied by its probability.
Objective Function Calculation:
Waiting Time: Calculated as the time patients (or the doctor) wait if the previous interval’s work extends into the current interval.
Doctor’s Overtime: Calculated as any time the doctor works beyond the total scheduled time.
Objective: The sum of weighted total waiting time and overtime.
Visualization:
Plots the objective values for all schedules, allowing us to visualize the impact of different scheduling configurations.
Interpreting the Results
Effect of Overbooking:
Scheduling multiple patients in the same interval increases the expected total work for that interval.
High total work can lead to increased waiting times and overtime.
Balancing Workload:
Distributing patients evenly across intervals can help minimize waiting times and overtime.
However, overbooking might still be beneficial if the service times are generally short.
Optimal Scheduling:
The schedules with the lowest objective values represent the best balance between patient waiting time and doctor’s overtime.
By analyzing the plot, we can identify these optimal schedules.
Understanding the Total Amount of Work
Variability in Service Times:
Since service times are random, the total amount of work in an interval is also random.
The expected total work helps in planning but doesn’t eliminate the risk of delays.
k-Fold Convolution:
Convolution accounts for all possible combinations of service times when patients are scheduled together.
It provides the probability distribution of the total work, which is essential for calculating expected waiting times and overtime.
Scheduling Decisions:
Knowledge of the total work distribution allows schedulers to make informed decisions about overbooking.
For instance, if service times have high variability, overbooking increases the risk of delays.
Practical Implications
Efficient Resource Utilization:
Understanding the total amount of work helps in optimizing the doctor’s schedule, ensuring they are neither overburdened nor underutilized.
Patient Satisfaction:
Minimizing waiting times improves patient experience.
Cost Management:
Reducing overtime helps in controlling operational costs.
Conclusion
By introducing the concept of the total amount of work in an interval and understanding its distribution through k-fold convolution of service times, we gain valuable insights into the scheduling problem. Ignoring no-shows simplifies the analysis, allowing us to focus on the impact of overbooking and service time variability on waiting times and overtime. This approach helps in designing schedules that optimize the objective function, balancing patient satisfaction with operational efficiency.
Next Steps
Incorporate No-Shows: Reintroducing the concept of no-shows would add complexity but provide a more realistic model.
Advanced Modeling: Utilize stochastic modeling techniques or simulations (e.g., Monte Carlo simulations) to account for variability in service times and no-shows.
Optimization Algorithms: Implement algorithms like integer programming, genetic algorithms, or heuristic methods to find optimal or near-optimal scheduling configurations in larger, more complex scenarios.
Definition of Latent Space
Latent Space refers to an abstract multi-dimensional space that represents the underlying structure or features of data that are not directly observed but can be inferred from observed variables. In operations research and data analysis, the latent space encapsulates hidden patterns, relationships, or variables that give rise to the observed outcomes. It is a conceptual space where each point corresponds to a set of latent variables influencing the system’s performance.
Latent Space in the Scheduling Problem
With the introduction of the total amount of work in each interval and the concept of k-fold convoluted service times (where \(k\) is the number of patients scheduled in a particular interval), we can now redefine and describe the latent space of the scheduling problem more precisely.
Components of the Latent Space
Scheduling Configurations:
Distribution of Indistinct Patients into Time Intervals: Patients are indistinct and are assigned to the available time intervals. Overbooking is allowed, so multiple patients can be scheduled in the same interval.
Possible Scheduling Combinations: For \(N\) indistinct patients and \(T\) intervals, the number of possible scheduling configurations is given by the combination formula:
\[
\text{Number of Scheduling Configurations} = \binom{N + T - 1}{N} = \binom{N + T - 1}{T - 1}
\]
This represents the number of ways to distribute \(N\) patients into \(T\) intervals.
Total Amount of Work in Each Interval:
k-Fold Convolution of Service Times: For each interval, the total work is the sum of service times of all patients scheduled in that interval. Since service times are random variables following a certain distribution, the total work is a random variable whose distribution is the convolution of the service time distribution, repeated \(k\) times, where \(k\) is the number of patients scheduled in that interval.
Distribution of Total Work: The total work in each interval has a probability distribution that depends on \(k\) and the service time distribution.
System Dynamics Influenced by Total Work:
Patient Waiting Times: The waiting time for patients depends on the cumulative total work from previous intervals and the total work in their scheduled interval.
Doctor’s Overtime: The total work across all intervals determines if the doctor finishes on time or incurs overtime.
Description of the Latent Space
The latent space of this scheduling problem is a multi-dimensional space where each dimension represents a variable or factor that influences the objective function. Specifically, it includes:
Patient Counts per Interval (\(k_i\)):
Each dimension corresponds to the number of patients scheduled in interval \(i\).
The latent space consists of all integer vectors \((k_1, k_2, \dots, k_T)\) satisfying \(k_i \geq 0\) and \(\sum_{i=1}^{T} k_i = N\).
Total Work Distributions (Stochastic Variables):
For each interval, the total amount of work is a random variable whose distribution depends on \(k_i\), the number of patients scheduled in that interval.
These distributions are derived from the k-fold convolution of the service time distribution.
Derived Performance Measures:
Expected Waiting Times: Calculated based on the total work distributions and scheduling configurations.
Expected Doctor’s Overtime: Determined by the cumulative total work and the length of the scheduled time.
Visualization of the Latent Space
Discrete Multi-Dimensional Space:
Each point in the latent space corresponds to a specific scheduling configuration represented by the patient counts per interval \((k_1, k_2, \dots, k_T)\).
The dimensions are the intervals, and the coordinates are the numbers of patients in each interval.
Mapping to Objective Function:
The latent space can be mapped to the objective function values (weighted sum of waiting times and overtime).
This mapping helps identify regions in the latent space where the objective function is minimized.
Implications of the Latent Space
Understanding System Behavior:
By exploring the latent space, we can understand how different distributions of patients across intervals (i.e., different \(k_i\)) and the associated total work distributions impact waiting times and overtime.
It highlights the trade-offs between overbooking (scheduling multiple patients in the same interval) and the risk of increased waiting times and overtime.
Optimization:
The latent space provides a framework for optimization algorithms to search for scheduling configurations that minimize the objective function.
It allows for the incorporation of stochastic elements (service time variability) into the optimization process.
Simplified Latent Space Ignoring No-Shows
By ignoring patient no-shows, the latent space becomes more tractable:
Deterministic Attendance: All scheduled patients are assumed to show up, eliminating the stochastic variables associated with no-show probabilities.
Focus on Service Time Variability:
The only stochastic elements are the service times, which affect the total work distributions.
This simplification allows us to concentrate on how scheduling decisions (patient counts per interval) and service time variability impact the system.
Example Illustration
Consider the small example with 5 indistinct patients and 3 time intervals:
Scheduling Configurations:
The possible configurations are all the combinations of non-negative integers \((k_1, k_2, k_3)\) satisfying \(k_1 + k_2 + k_3 = 5\).
There are \(\binom{5 + 3 - 1}{5} = 21\) possible scheduling configurations.
This forms the deterministic part of the latent space.
Total Work Distributions:
For each interval, calculate the total work distribution based on the number of patients scheduled (\(k_i\)) and the service time distribution.
The total work is a random variable with a distribution obtained via the k-fold convolution of the service time distribution.
Objective Function Values:
For each scheduling configuration, compute the expected waiting times and doctor’s overtime using the total work distributions.
Map each point in the latent space (scheduling configuration \((k_1, k_2, k_3)\)) to its corresponding objective function value.
Key Takeaways
Latent Space as a Framework:
Provides a comprehensive framework to capture all possible scheduling scenarios and their implications.
Integrates both the deterministic scheduling decisions (patient counts per interval) and the stochastic nature of service times.
Insights for Scheduling:
Helps identify optimal scheduling configurations that balance patient waiting times and doctor’s overtime.
Enables analysis of the impact of overbooking and service time variability on system performance.
Foundation for Optimization:
The detailed description of the latent space is essential for developing and applying optimization algorithms.
It supports the use of techniques like stochastic optimization, Monte Carlo simulations, and heuristic methods.
Conclusion
The latent space of the scheduling problem is a multi-dimensional construct that encapsulates all possible scheduling configurations (in terms of patient counts per interval) and the associated probabilistic outcomes due to service time variability. By defining and analyzing this latent space, we gain a deeper understanding of the factors influencing the objective function. This understanding is crucial for designing efficient schedules that minimize patient waiting times and doctor’s overtime, ultimately improving the overall performance of the scheduling system.
Summary
Latent Space Definition: An abstract space representing underlying variables that influence observed outcomes but are not directly observable.
In the Scheduling Problem:
Dimensions: Number of patients scheduled in each interval (\(k_i\)) and total work distributions per interval.
Variables: Deterministic (patient counts per interval) and stochastic (service times).
Purpose: To analyze and optimize the scheduling configurations to minimize the objective function.
By comprehensively describing the latent space with the concept of total amount of work and k-fold convolution of service times, we can effectively explore and optimize the scheduling problem, leading to better resource utilization and enhanced patient and provider satisfaction.