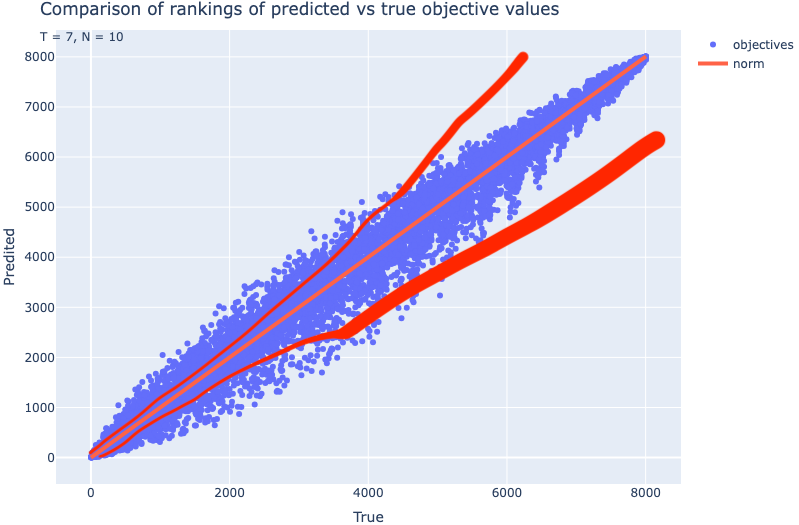
Ik test de snelheid van de het huidige XGBoost model t.o.v. de berekende waarde.
We maken een mix van berekening van de werkelijke waarde en berekening via het model. Hiervoor moeten we kijken of het model bij de waarde ook een inschatting van de betrouwbaarheid kan geven. Als de betrouwbaarheid laag is, wordt de werkelijke waarde berekend.
2024-07-16 16:27:33.801982: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
N =10T =7d =3s = [0.0, 0.27, 0.28, 0.2, 0.15, 0.1]indices = np.arange(len(s))exp_s = (indices * s).sum()q =0.2s_adj = service_time_with_no_shows(s, q)indices = np.arange(len(s_adj))exp_s_adj = (indices * s_adj).sum()print(f'service time distribution with no-shows: {s_adj} with expcted value: {exp_s_adj}')omega =0.5samples_names = [f'x_{t}'for t inrange(T)]samples = pd.DataFrame(columns = samples_names)labels_names = [f'ew_{t}'for t inrange(T)]labels = pd.DataFrame(columns = labels_names)schedules = generate_all_schedules(N, T) # Generates all possible schedules with length Tprint(f'N = {N}, # of schedules = {len(schedules)}')for schedule in schedules: x = np.array(schedule, dtype=np.int64) sch = run_schedule(x, d, s, q, omega, False)# Convert the current data dictionary to a DataFrame and append it to the main DataFrame temp_samples = pd.DataFrame([x], columns=samples_names) samples = pd.concat([samples, temp_samples], ignore_index=True) temp_labels = pd.DataFrame([sch.system['ew']], columns=labels_names) labels = pd.concat([labels, temp_labels], ignore_index=True)samples = samples.astype(np.int64)labels = labels.astype(np.float64)labels['obj'] = labels.sum(axis=1)labels['obj_rank'] = labels['obj'].rank().astype(np.float64)samples.tail()labels.tail()
service time distribution with no-shows: [0.2, 0.21600000000000003, 0.22400000000000003, 0.16000000000000003, 0.12, 0.08000000000000002] with expcted value: 2.024
N = 10, # of schedules = 8008
/var/folders/gf/gtt1mww524x0q33rqlwsmjw80000gn/T/ipykernel_77102/458601458.py:29: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.