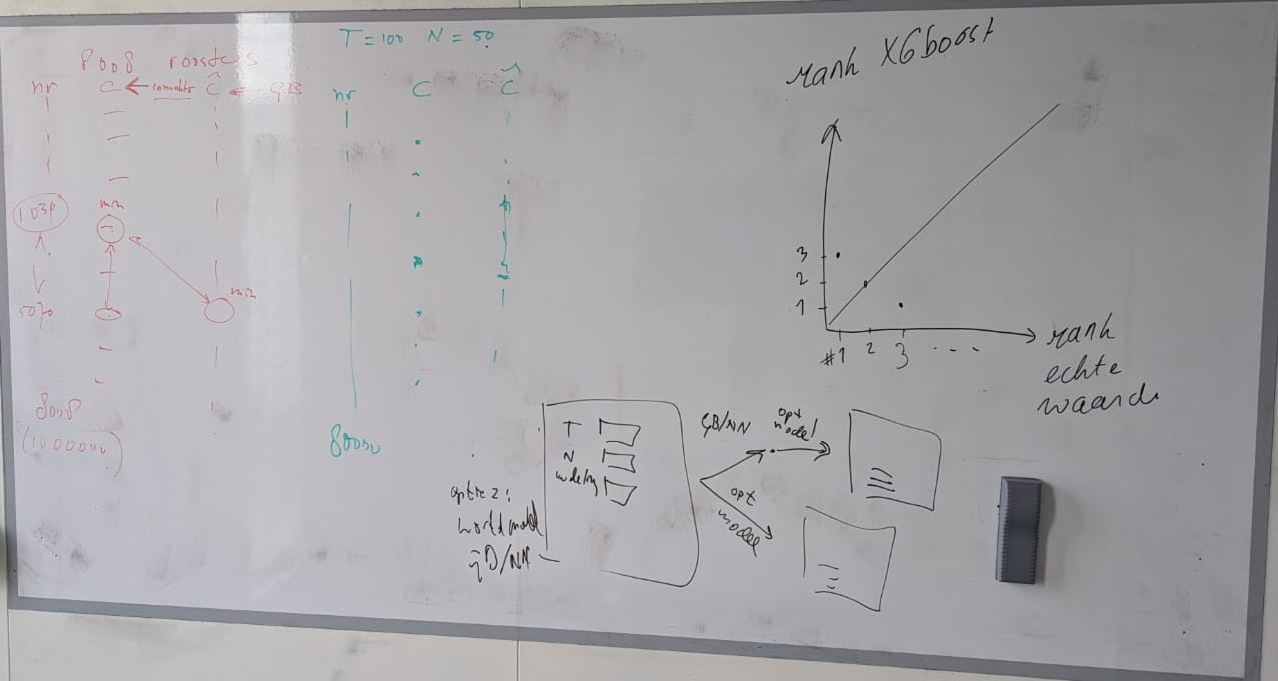
Welke onderdelen van de workflow kunnen parallel worden uitgevoerd?
Idee Joost: cardinal analysis - is schedule A better than B? -> Yes/No
Idee Witek: Als een model is getraind op een set schedules met lengte T en de output is de reeks wachttijden voor ieder interval, dan kan ook iedere schedule met een lengte korter dan T met hetzelfde model worden bepaald. Stel het model is getraind op T = 7. Dan kan iedere schedule T = 5 ook direct worden ingevoerd als [x_0, x_1, x_2, x_3, x_4, 0, 0]. Sterker nog: met x_5 = 1 wordt in dit geval overwerk ook berekend.
Notities overleg 04-07-2024
Experiment: Application of ML models to calculate loss values
In this experiment we will try out several Machine Learning models to predict the outcome of a loss function from a given schedule with T intervals of length d. A schedule with N patients can be defined as a vector
x = (x_1, x_2, \ldots, x_T) \in \mathbb{N}_0^T
\text{ such that } \sum_{t=1}^{T} x_t = N.
Waiting times are calculated using a Lindley recursion:
W_{1, t} = \max(0, W_{1, t-1} + V_{t-1} - d)
W_{n, t} = W_{1,t} * S^{(n-1)}
where W_{n, t} is the waiting time distribution of patient n in interval t, V_{T} is the distribution of the total amount of work in the last interval, S^{(k)} is the k-fold convolution of the service time distribution S and W*S is the convolution of the waiting time distribtion W with S.
We are interested in calculating for each schedule x the expected total waiting time and overtime
The loss function is a weighted average of expected waiting time and overtime
C(x) = \alpha_W E(W(x)) + \alpha_L E(L(x))
Directly mapping schedules to loss values would significantly reduce the practical applicability of our method. The weights in the loss function are subjective values that reflect the perceived relative importance of their corresponding factors. Consequently, each time the weights are adjusted, the model would need to be retrained.
A more effective approach would be to train separate models for each factor in the loss function. Once we predict the levels of each factor, we can input them into the loss function using the desired weights. In this experiment we will even go a step further and try to predict the expected waiting times in each interval instead of the aggregated values for the whole schedule.
Setup
Load all packages, the schedule class and selected functions.
Warning
This code chunk contains an important variable run_flag. If it’s set to False, some code further in the notebook will not run. You can use this to save on execution times when making minor changes.
from schedule_class import NewSchedule, generate_schedules, service_time_with_no_showsfrom functions import generate_all_schedulesimport numpy as npimport pandas as pdimport xgboost as xgbfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_errorimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Input, Conv2D, Flatten, Denseimport plotly.express as pxfrom plotly.subplots import make_subplotsimport plotly.graph_objects as goimport hashlibimport timedef compute_hash(lst):""" Compute a hash for a given list of items. """ hasher = hashlib.md5()for item in lst:# Convert each item to a string and then encode it to bytes hasher.update(str(item).encode('utf-8'))return hasher.hexdigest()def save_hash(hash_value, hash_file):withopen(hash_file, 'w') as f: f.write(hash_value)def load_hash(hash_file):try:withopen(hash_file, 'r') as f:return f.read().strip()exceptFileNotFoundError:returnNonehash_file ='data_hash.txt'saved_hash = load_hash(hash_file)run_flag =True# Switch to run highly intensive code
2024-07-10 14:02:33.948670: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Runner functions for creating and running a schedule instance.
Generate a dataset for training and testing of various schedules of lenght T = 10 with N \in \{1, \dots, 14\} and corresponding aggregated expected waiting times in each interval.
service time distribution with no-shows: [0.2, 0.21600000000000003, 0.22400000000000003, 0.16000000000000003, 0.12, 0.08000000000000002] with expcted value: 2.024
if(run_flag):# Start timing start_time = time.time() samples_names = [f'x_{t}'for t inrange(T)] samples = pd.DataFrame(columns = samples_names) labels_names = [f'ew_{t}'for t inrange(T)] labels = pd.DataFrame(columns = labels_names)for n inrange(1, max_N+1): schedules = generate_all_schedules(n, T) # Generates all possible schedules with length Tprint(f'N = {n}, # of schedules = {len(schedules)}')for schedule in schedules: x = np.array(schedule, dtype=np.int64) sch = run_schedule(x, d, s, q, omega, False)# Convert the current data dictionary to a DataFrame and append it to the main DataFrame temp_samples = pd.DataFrame([x], columns=samples_names) samples = pd.concat([samples, temp_samples], ignore_index=True) temp_labels = pd.DataFrame([sch.system['ew']], columns=labels_names) labels = pd.concat([labels, temp_labels], ignore_index=True) samples = samples.astype(np.int64) labels = labels.astype(np.float64)print(f'samples: {samples.tail()}\nlabels: {labels.tail()}')# End timing end_time = time.time()# Calculate elapsed time elapsed_time = end_time - start_timeprint(f"\nExecution time: {elapsed_time:.2f} seconds")
N = 1, # of schedules = 7
N = 2, # of schedules = 28
N = 3, # of schedules = 84
N = 4, # of schedules = 210
N = 5, # of schedules = 462
N = 6, # of schedules = 924
N = 7, # of schedules = 1716
N = 8, # of schedules = 3003
N = 9, # of schedules = 5005
N = 10, # of schedules = 8008
samples: x_0 x_1 x_2 x_3 x_4 x_5 x_6
19442 9 0 0 0 1 0 0
19443 9 0 0 1 0 0 0
19444 9 0 1 0 0 0 0
19445 9 1 0 0 0 0 0
19446 10 0 0 0 0 0 0
labels: ew_0 ew_1 ew_2 ew_3 ew_4 ew_5 ew_6
19442 72.864 0.000000 0.000000 0.000000 6.380606 0.0 0.0
19443 72.864 0.000000 0.000000 9.241482 0.000000 0.0 0.0
19444 72.864 0.000000 12.217883 0.000000 0.000000 0.0 0.0
19445 72.864 15.216038 0.000000 0.000000 0.000000 0.0 0.0
19446 91.080 0.000000 0.000000 0.000000 0.000000 0.0 0.0
Execution time: 95.83 seconds
/var/folders/gf/gtt1mww524x0q33rqlwsmjw80000gn/T/ipykernel_57197/225948540.py:21: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
Model saved to xgboost_models/xgboost_model_int0.json
Execution time: 0.06 seconds
Interval 0, MSE: 7.148421734207526e-07
Model saved to xgboost_models/xgboost_model_int1.json
Execution time: 0.09 seconds
Interval 1, MSE: 0.0611198632052405
Model saved to xgboost_models/xgboost_model_int2.json
Execution time: 0.07 seconds
Interval 2, MSE: 0.49045906911557013
Model saved to xgboost_models/xgboost_model_int3.json
Execution time: 0.04 seconds
Interval 3, MSE: 0.7915373814093815
Model saved to xgboost_models/xgboost_model_int4.json
Execution time: 0.05 seconds
Interval 4, MSE: 1.1025974062262889
Model saved to xgboost_models/xgboost_model_int5.json
Execution time: 0.06 seconds
Interval 5, MSE: 1.1965081678551843
Model saved to xgboost_models/xgboost_model_int6.json
Execution time: 0.12 seconds
Interval 6, MSE: 1.3469828465500635
interval actual predicted
0 0 0.000 0.000257
1 0 20.240 20.238684
2 0 0.000 0.000257
3 0 0.000 0.000257
4 0 12.144 12.143320
...
interval actual predicted
27225 6 0.597160 1.255238
27226 6 0.000000 1.279314
27227 6 0.000000 0.321677
27228 6 2.330257 1.858447
27229 6 0.000000 -0.070595
Execution time: 0.50 seconds
/var/folders/gf/gtt1mww524x0q33rqlwsmjw80000gn/T/ipykernel_57197/3046832058.py:19: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
# Define the number of rows and columns for the subplot gridrows = (T +2) //3# Number of rows, adjust based on the total number of plots (adding 2 to ensure we have enough rows)cols =3# Number of columns# Create a subplot figurefig = make_subplots(rows=rows, cols=cols, subplot_titles=[f'Interval {t}'for t inrange(T)])def add_jitter(values, jitter_amount=0.0):return values + np.random.uniform(-jitter_amount, jitter_amount, len(values))for t inrange(T): comparison_df = results[results['interval'] == t]# Add jitter to actual and predicted values jittered_actual = add_jitter(comparison_df['actual']) jittered_predicted = add_jitter(comparison_df['predicted'])# Get the row and column index for the current plot row = (t // cols) +1 col = (t % cols) +1# Add the scatter plot with jittered points to the subplot figure fig.add_trace( go.Scatter(x=jittered_actual, y=jittered_predicted, mode='markers', name=f'Interval {t}', showlegend=False), row=row, col=col )# Round the MSE value to two decimals rounded_mse =round(mse_list[t], 2)# Update subplot title with MSE fig.layout.annotations[t].text =f'Interval {t}</br></br><sub>MSE = {rounded_mse}, # Samples = {len(comparison_df["actual"])}</sub>'# Update the layout of the subplot figurefig.update_layout( height=1000, # Adjust height as needed width=1200, # Adjust width as needed title_text="XGBoost: Actual vs Predicted Waiting Times Across Intervals", title={'y': 0.95, # Position the title closer to the top'x': 0.5, # Center the title'xanchor': 'center','yanchor': 'top' }, margin=dict(l=150, r=20, t=180, b=100) # Add top margin to create space between title and plots)# Add shared axis labelsfig.add_annotation(dict(font=dict(size=16), x=0.5, y=-0.1, showarrow=False, text="Actual", xref="paper", yref="paper"))fig.add_annotation(dict(font=dict(size=16), x=-0.1, y=0.5, showarrow=False, text="Predicted", textangle=-90, xref="paper", yref="paper"))# Print the grid layout to debug the row and column indexfig.print_grid()# Show the figurefig.show()
This is the format of your plot grid:
[ (1,1) x,y ] [ (1,2) x2,y2 ] [ (1,3) x3,y3 ]
[ (2,1) x4,y4 ] [ (2,2) x5,y5 ] [ (2,3) x6,y6 ]
[ (3,1) x7,y7 ] [ (3,2) x8,y8 ] [ (3,3) x9,y9 ]
Function Definition:
The function xgboost_workflow takes two arguments: X (the feature set) and y (the target variable).
Data Preparation:
The function splits the data into training and testing sets using train_test_split from the sklearn.model_selection module.
X_train and X_test are the training and testing subsets of the feature set, respectively.
y_train and y_test are the corresponding subsets of the target variable.
The test_size parameter is set to 0.2, meaning 20% of the data is used for testing, and 80% for training.
The random_state parameter ensures reproducibility by seeding the random number generator.
Model Training Parameters:
A dictionary params is defined to set the hyperparameters for the XGBoost model:
'objective': 'reg:squarederror' specifies that the objective function is regression using squared error.
'max_depth': 3 sets the maximum depth of the trees to 3, controlling the complexity of the model.
'eta': 0.1 sets the learning rate to 0.1, controlling the step size during optimization.
'verbosity': 1 sets the verbosity level to 1, providing basic information about the training process.
Number of Rounds:
num_round is set to 100, indicating the number of boosting rounds (iterations) the model will undergo.
DMatrix Creation:
The training and testing datasets are converted into DMatrix objects, which are the internal data structure that XGBoost uses.
dtrain is the DMatrix for the training set, created with X_train and y_train.
dtest is the DMatrix for the testing set, created with X_test and y_test.
Model Training:
The XGBoost model is trained using the xgb.train function, which takes the parameters, the training DMatrix, and the number of rounds as inputs.
The trained model is returned as the output of the function.
Learning Task Parameters:
objective: Defines the loss function to be minimized (e.g., reg:squarederror, binary:logistic, multi:softmax).
Tree Parameters:
max_depth: Maximum depth of the decision trees. Larger values can lead to overfitting.
min_child_weight: Minimum sum of instance weight (hessian) needed in a child.
gamma: Minimum loss reduction required to make a further partition on a leaf node.
Booster Parameters:
eta (alias: learning_rate): Step size shrinkage used to prevent overfitting.
subsample: Proportion of training instances to use for each tree. Helps prevent overfitting.
colsample_bytree: Subsample ratio of columns when constructing each tree.
lambda (alias: reg_lambda): L2 regularization term on weights.
alpha (alias: reg_alpha): L1 regularization term on weights.
Learning Task Customization:
scale_pos_weight: Control the balance of positive and negative weights, useful for unbalanced classes.
eval_metric: Evaluation metrics to be used (e.g., rmse, logloss, error).
Control Parameters:
n_estimators: Number of trees to fit (number of boosting rounds).
early_stopping_rounds: Stop training if one metric doesn’t improve after a given number of rounds.
Tree Method Parameters:
tree_method: Algorithm used to construct trees (e.g., auto, exact, approx, hist, gpu_hist).
grow_policy: Controls the growth policy for the trees. depthwise or lossguide.
Adjusting these parameters allows for fine-tuning the XGBoost model to better fit the data and improve performance.
X_c = X.valuesy_c = y.values# Reshape X to have the shape (samples, height, width, channels)X_c = X_c.reshape((X_c.shape[0], X_c.shape[1], 1, 1))print(X_c.shape[0], X_c.shape[1])# Split into training and testing datasetsX_train_c, X_test_c, y_train_c, y_test_c = train_test_split(X_c, y_c, test_size=0.9, random_state=42)
19447 7
# Build the modelmodel_c = Sequential()model_c.add(Input(shape=(X_c.shape[1], 1, 1)))model_c.add(Conv2D(64, (2, 1), activation='relu'))model_c.add(Flatten())model_c.add(Dense(64, activation='relu'))model_c.add(Dense(y_c.shape[1])) # Output layer with T units (one for each output value)# Compile the modelmodel_c.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy'])# Print model summarymodel_c.summary()
# Evaluate the modelif(run_flag): loss = model_c.evaluate(X_test_c, y_test_c, verbose=2)# Make predictions predictions = model_c.predict(X_test_c)def calculate_mse(array1, array2):""" Calculate the Mean Squared Error between two arrays. Parameters: array1 (np.ndarray): The first array. array2 (np.ndarray): The second array. Returns: float: The Mean Squared Error between the two arrays. """# Ensure the input arrays are NumPy arrays array1 = np.array(array1) array2 = np.array(array2)# Calculate the MSE mse = np.mean((array1 - array2) **2)return mse mse_cnn = [calculate_mse(y_test_c[t], predictions[t]) for t inrange(T)] mse_cnn
# Define the number of rows and columns for the subplot gridrows = (T +2) //3# Number of rows, adjust based on the total number of plots (adding 2 to ensure we have enough rows)cols =3# Number of columns# Create a subplot figurefig = make_subplots(rows=rows, cols=cols, subplot_titles=[f'Interval {t}'for t inrange(T)])for t inrange(T):# Get the row and column index for the current plot row = (t // cols) +1 col = (t % cols) +1# Add the scatter plot with jittered points to the subplot figure fig.add_trace( go.Scatter(x=y_test_c[:,t], y=predictions[:,t], mode='markers', name=f'Interval {t}', showlegend=False), row=row, col=col )# Update subplot title with MSE fig.layout.annotations[t].text =f'Interval {t}</br></br><sub>MSE = {round(mse_cnn[t], 2)}, # Samples = {len(y_test_c)}</sub>'# Update the layout of the subplot figurefig.update_layout( height=1000, # Adjust height as needed width=1200, # Adjust width as needed title_text="CNN: Actual vs Predicted Waiting Times Across Intervals", title={'y': 0.95, # Position the title closer to the top'x': 0.5, # Center the title'xanchor': 'center','yanchor': 'top' }, margin=dict(l=150, r=20, t=180, b=100) # Add top margin to create space between title and plots)# Add shared axis labelsfig.add_annotation(dict(font=dict(size=16), x=0.5, y=-0.1, showarrow=False, text="Actual", xref="paper", yref="paper"))fig.add_annotation(dict(font=dict(size=16), x=-0.1, y=0.5, showarrow=False, text="Predicted", textangle=-90, xref="paper", yref="paper"))# Print the grid layout to debug the row and column indexfig.print_grid()# Show the figurefig.show()
This is the format of your plot grid:
[ (1,1) x,y ] [ (1,2) x2,y2 ] [ (1,3) x3,y3 ]
[ (2,1) x4,y4 ] [ (2,2) x5,y5 ] [ (2,3) x6,y6 ]
[ (3,1) x7,y7 ] [ (3,2) x8,y8 ] [ (3,3) x9,y9 ]
Ranking
N =10T =7d =3s = [0.0, 0.27, 0.28, 0.2, 0.15, 0.1]indices = np.arange(len(s))exp_s = (indices * s).sum()q =0.2s_adj = service_time_with_no_shows(s, q)indices = np.arange(len(s_adj))exp_s_adj = (indices * s_adj).sum()print(f'service time distribution with no-shows: {s_adj} with expcted value: {exp_s_adj}')omega =0.5samples_names = [f'x_{t}'for t inrange(T)]samples = pd.DataFrame(columns = samples_names)labels_names = [f'ew_{t}'for t inrange(T)]labels = pd.DataFrame(columns = labels_names)schedules = generate_all_schedules(N, T) # Generates all possible schedules with length Tprint(f'N = {n}, # of schedules = {len(schedules)}')for schedule in schedules: x = np.array(schedule, dtype=np.int64) sch = run_schedule(x, d, s, q, omega, False)# Convert the current data dictionary to a DataFrame and append it to the main DataFrame temp_samples = pd.DataFrame([x], columns=samples_names) samples = pd.concat([samples, temp_samples], ignore_index=True) temp_labels = pd.DataFrame([sch.system['ew']], columns=labels_names) labels = pd.concat([labels, temp_labels], ignore_index=True)samples = samples.astype(np.int64)labels = labels.astype(np.float64)print(f'samples: {samples.tail()}\nlabels: {labels.tail()}')loaded_model = xgb.Booster()
/var/folders/gf/gtt1mww524x0q33rqlwsmjw80000gn/T/ipykernel_57197/3445281602.py:29: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.